接續前一天,探討了 CloudWatch Insight 上的 metrics 及 node 上的差異。本日將探討 Linux Virtual Ethernet Device(veth) [1] 及 Ethernet Device(eth) 上 RX/TX metrics 為何計算上會有些差異。
dd 命令產生一個 512MB 檔案。$ cd /usr/share/nginx/html
$ sudo dd if=/dev/zero of=./512MB-file.txt count=1024 bs=524288
1024+0 records in
1024+0 records out
536870912 bytes (537 MB) copied, 2.57196 s, 209 MB/s
$ ll -h
total 513M
drwxr-xr-x 2 root root 78 Oct 5 13:16 ./
drwxr-xr-x 4 root root 33 Dec 3 2019 ../
-rw-r--r-- 1 root root 3.6K Aug 28 2019 404.html
-rw-r--r-- 1 root root 3.7K Aug 28 2019 50x.html
-rw-r--r-- 1 root root 512M Oct 5 13:16 512MB-file.txt
-rw-r--r-- 1 root root 3.7K Apr 30 2020 index.html
curl 常用工具命令。$ cat ./netshoot.yaml
apiVersion: v1
kind: Pod
metadata:
name: netshoot
spec:
containers:
- name: netshoot
image: nicolaka/netshoot:latest
command:
- sleep
- "affinity"
imagePullPolicy: IfNotPresent
restartPolicy: Always
netshoot Pod。$ kubectl apply -f ./netshoot.yaml
pod/netshoot created
ip-192-168-55-245.eu-west-1.compute.internal 上。$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
netshoot 1/1 Running 0 63s 192.168.41.36 ip-192-168-55-245.eu-west-1.compute.internal <none> <none>
[ec2-user@ip-192-168-55-245 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:39:dc:28:ad:03 brd ff:ff:ff:ff:ff:ff
inet 192.168.55.245/19 brd 192.168.63.255 scope global dynamic eth0
valid_lft 3452sec preferred_lft 3452sec
inet6 fe80::839:dcff:fe28:ad03/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:92:eb:9f:86:db brd ff:ff:ff:ff:ff:ff
inet 192.168.50.176/19 brd 192.168.63.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::892:ebff:fe9f:86db/64 scope link
valid_lft forever preferred_lft forever
4: eni3c1ae1f0141@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP group default
link/ether 86:4e:9b:5d:37:2f brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::844e:9bff:fe5d:372f/64 scope link
valid_lft forever preferred_lft forever
12: enie348bef9edc@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP group default
link/ether 72:b2:3d:8b:97:96 brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::70b2:3dff:fe8b:9796/64 scope link
valid_lft forever preferred_lft forever
netshoot Pod process id。[ec2-user@ip-192-168-55-245 ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
12647132137e nicolaka/netshoot "sleep infinity" 4 minutes ago Up 4 minutes k8s_netshoot_netshoot_default_daabb0d8-ebc2-45de-a3ab-9db38faa6ac7_0
...
...
[ec2-user@ip-192-168-55-245 ~]$ docker inspect 12647132137e -f '{{.State.Pid}}'
26636
nsenter 命令使用與 process 26636 相同的 namespace 查看網卡資訊,可以與 kubectl 命令比對輸出皆可以查看 Pod 內 eth0 IP 為 192.168.41.36。[ec2-user@ip-192-168-55-245 ~]$ sudo nsenter -t 26636 -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP group default
link/ether be:c1:97:6b:13:b7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.41.36/32 scope global eth0
valid_lft forever preferred_lft forever
$ kubectl exec -it netshoot -- ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP group default
link/ether be:c1:97:6b:13:b7 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.41.36/32 scope global eth0
valid_lft forever preferred_lft forever
a. 透過 kubectl 命令下載 Nginx server 上的 512MB-file.txt 檔案。
$ kubectl exec -it netshoot -- curl ec2-34-243-235-xxx.eu-west-1.compute.amazonaws.com/512MB-file.txt --output ./512.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 512M 100 512M 0 0 78.0M 0 0:00:06 0:00:06 --:--:-- 75.2M
b. 於 worker node 上擷取所有 interface 上的封包。
$ sudo tcpdump -i any -w host.pcap
c. 於 worker node 上擷取 netshoot Pod(process id 26636) 上的封包。
$ sudo nsenter -t 26636 -n tcpdump -i any -w container.pcap
透過 tshark 命令方式過濾 sequence number,以下隨機選取 sequence number 為 75297。分別於 host.pcap 及 container.pcap 上觀察到,從 Nginx 返回的封包,會先經由 eth0 192.168.55.245 在轉至 veth 至 Pod eth0 192.168.41.36。
$ tshark -r ./host.pcap -Y "tcp.seq == 75297"
355 0 34.243.235.xxx -> 192.168.55.245 TCP 5860 [TCP segment of a reassembled PDU]
356 0 34.243.235.xxx -> 192.168.41.36 TCP 5860 [TCP segment of a reassembled PDU]
$ tshark -r ./container.pcap -Y "tcp.seq == 75297"
47 0 34.243.235.xxx -> 192.168.41.36 TCP 5860 [TCP segment of a reassembled PDU]
同時,使用封包數量來最比對,也能觀察到於 EC2 作業系統層級擷取的的數量遠大於 container 層級。
$ tshark -r ./container.pcap | wc -l
50824
$ tshark -r ./host.pcap | wc -l
80683
一般來說,我們可以藉由 ifconfig 或是 ip a 命令查看對應的 RX/TX packets、bytes、errors 及 dropped 資訊。
$ ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001
inet 192.168.55.245 netmask 255.255.224.0 broadcast 192.168.63.255
inet6 fe80::839:dcff:fe28:ad03 prefixlen 64 scopeid 0x20<link>
ether 0a:39:dc:28:ad:03 txqueuelen 1000 (Ethernet)
RX packets 136014 bytes 171417004 (163.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 35029 bytes 6289749 (5.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
根據 VPC CNI plugin Proposal [3]。當一個 Pod 發出一個 request 到外部網路如 www.yahoo.com 網站,其流程如下:
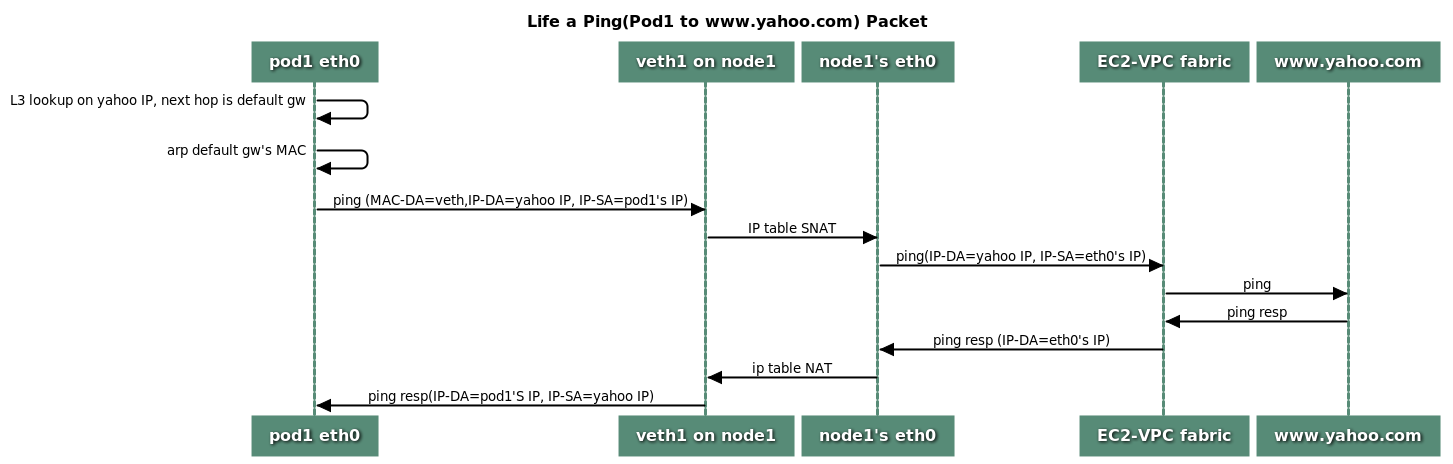
來源: Proposal: CNI plugin for Kubernetes networking over AWS VPC
由上述流程,封包會先由 node 上 eth device 轉發至 veth 最終進入至 Pod 內 eth0 device,與實驗相符合。
接著,在 Linux 文件内提及了 ifconfig 主要讀取 /proc/net/dev 並針對個別網路裝置計算 RX/TX metrics[4],查看當前 EKS AMI 所使用的 kernel 5.4 版本,其中 dev_seq_printf_stats [5]函式所带入参数为網路裝置(struct net_device *dev)。
[ec2-user@ip-192-168-55-245 ~]$ uname -a
Linux ip-192-168-55-245.eu-west-1.compute.internal 5.4.209-116.363.amzn2.x86_64 #1 SMP Wed Aug 10 21:19:18 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
[ec2-user@ip-192-168-55-245 ~]$ sudo cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
eth0: 2052337175 1676715 0 0 0 0 0 0 1285891238 1208605 0 0 0 0 0 0
eni3c1ae1f0141: 656047 6236 0 0 0 0 0 0 637836 6145 0 0 0 0 0 0
lo: 1707704 25689 0 0 0 0 0 0 1707704 25689 0 0 0 0 0 0
enie348bef9edc: 6399336 96933 0 0 0 0 0 0 1543213684 139781 0 0 0 0 0 0
eth1: 2492 89 0 0 0 0 0 0 1130 15 0 0 0 0 0 0
static void dev_seq_printf_stats(struct seq_file *seq, struct net_device *dev)
{
struct rtnl_link_stats64 temp;
const struct rtnl_link_stats64 *stats = dev_get_stats(dev, &temp);
seq_printf(seq, "%6s: %7llu %7llu %4llu %4llu %4llu %5llu %10llu %9llu "
"%8llu %7llu %4llu %4llu %4llu %5llu %7llu %10llu\n",
dev->name, stats->rx_bytes, stats->rx_packets,
stats->rx_errors,
stats->rx_dropped + stats->rx_missed_errors,
stats->rx_fifo_errors,
stats->rx_length_errors + stats->rx_over_errors +
stats->rx_crc_errors + stats->rx_frame_errors,
stats->rx_compressed, stats->multicast,
stats->tx_bytes, stats->tx_packets,
stats->tx_errors, stats->tx_dropped,
stats->tx_fifo_errors, stats->collisions,
stats->tx_carrier_errors +
stats->tx_aborted_errors +
stats->tx_window_errors +
stats->tx_heartbeat_errors,
stats->tx_compressed);
}
其中在 git commit [6] 上增加 rx_dropped counter 提到:當一個 device 向 linux kernel network stack 提供一個 packet,會再進入 protocol stack 前丟棄。故確認當有封包經過 device 時,該 device 的 RX/TX counter 會計算相應的數值。以下節錄該 commit 的原文内容:
net: add a core netdev-gt; rx_dropped counter
In various situations, a device provides a packet to our stack and we drop it before it enters protocol stack :
- softnet backlog full (accounted in /proc/net/softnet_stat)
- bad vlan tag (not accounted)
- unknown/unregistered protocol (not accounted)
We can handle a per-device counter of such dropped frames at core level,
and automatically adds it to the device provided stats (rx_dropped), so
that standard tools can be used (ifconfig, ip link, cat /proc/net/dev)
This is a generalization of commit 8990f468a (net: rx_dropped
accounting), thus reverting it.
Amazon VPC CNI Plugin 訪問外網流程及 Linux 作業系統上 RX/TX 計算方式,封包皆會先經過 eth 再轉發至 veth,因此可以確認 eth 網路接口上的 RX/TX 也會重複計算到 veth 上的數值。


 iThome鐵人賽
iThome鐵人賽